









Genom att tänka om cacheminnet i en processor presenterar forskare ett processorsystem som är både snabbare och effektivare än dagens lösningar.
I princip alla moderna X86-processorer – samt många kretsar med annan arkitektur – använder idag samma grunddesign för cacheminne, det vill säga det minne som finns inbakat i processorn för att hantera små mängder data betydligt snabbare än vad som är möjligt med RAM. Minnet finns indelat i ett antal nivåer, där de lägre nivåerna ligger närmare processorkärnorna och är snabbare, medan högre cacheminne rymmer mer data men är långsammare.
Ett dynamiskt cacheminne
Nu har forskare på MIT presenterat simulerade tester på en processor som använder en helt ny struktur på cacheminnet, vilket ska ge såväl bättre prestanda som högre energieffektivtet. Modellen, som kallas Jenga, bygger på att cacheminnet placeras i ett rutnät av likvärdiga minneskretsar. Hur snabbt en processorkärna kan läsa från en sådan “ruta” av minne avgörs av hur långt det fysiska avståndet mellan dem är.
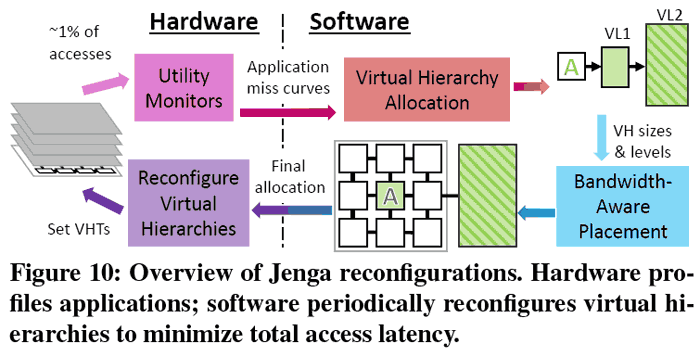
Därefter används mjukvara för att strategiskt sprida ut information över cacheminnet, antingen utspritt över flera cacheenheter längre bort om det är större datamängder, eller placerat precis intill kärnan för mindre mängder som behöver användas snabbare.
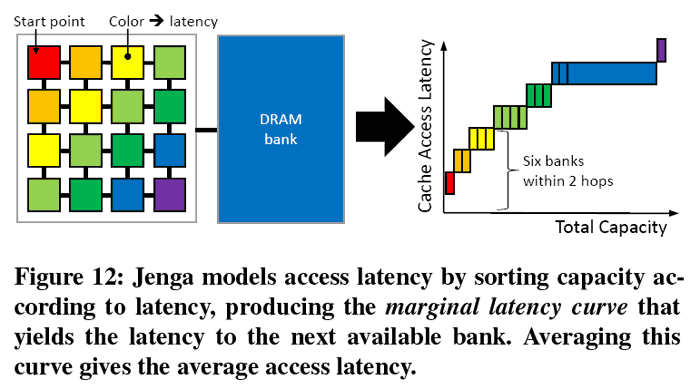
Just möjligheten att dynamiskt kunna välja hur cachestrukturen ska se ut ska enligt forskarna innebära mellan 20 och 30 procent bättre prestanda än motsvarande processor med dagens cacheteknik. Samtidigt uppges Jenga medföra mellan 30 och 85 procent bättre energieffektivitet.
Precis som all experimentell teknik finns det fortfarande en krokig väg mellan ritbordet och faktiska produkter – nu väntar bland annat fler tester, både simulerade och fysiska. Det finns dock inga egentliga tekniska hinder för Jenga eller liknande tekniker att implementeras i färdiga processorer inom en snar framtid.



