








GF100 - Arkitektur
Som i princip alla av er vet vid det här laget är arkitekturens kodnamn Fermi, efter den italienska fysikern Enrico Fermi och fysik är något som genomsyrat hela projektet – enligt NVIDIA är detta anledningen till kretsarnas försening då man inte fått allting att fungera precis som man viljat. Nu är vi dock här och resultatet är den största förändringen sedan tillverkarens G80-arkitektur, lanserad 2006, kretsarna är officiellt döpta GF100 (GeForce Fermi 100).
Vi har ännu inga detaljer om hur resterande DirectX11-kompatibla kretsar från NVIDIA kommer se ut, men tillverkaren lovar en övergång till DX11-kapabla kretsar över hela sortimentet inom 12 månader. I brist på övriga släktingar att analysera får vi helt enkelt börja dissekera GF100 med en gång. Uppbyggnaden och en genomgång av’ densamma finner ni nedan.

GF100-kärnan – 16 processorer uppdelade i 32 kärnor var
NVIDIA har gått den svåra vägen med en enorm kärna uppbygd av inte mindre än 3.0 miljarder transistorer. Denna består i sin tur inte av inte mindre än 16 “Streaming Multiprocessors” (SM), dvs något som skulle kunna liknas vid CPU:er som i sin tur sedan har 32 CUDA Cores, shaders, dessa kan liknas vid vanliga CPU-kärnor då beräkningarna sker i dessa. Varje SM har en L1-cache på 16/48KB att tilgå, utöver detta delar kärnorna sedan på en gemensam L2-cache på 768KB. Att L1-cachen är listad som 16 eller 48KB beror på att varje SM har 64KB minne att tillgå, denna kan delas upp som 16KB L1-cache eller användas som delat minne, resterande 48KB används där det behövs mest.
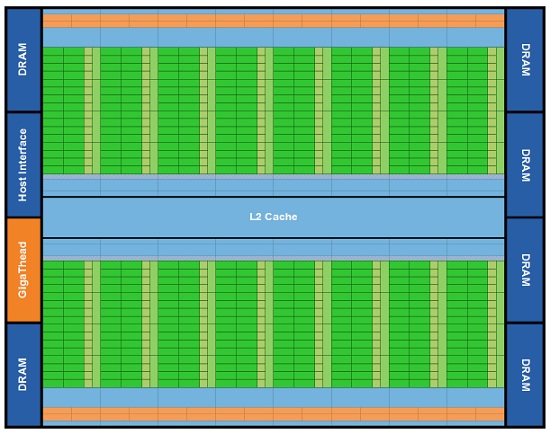
Hur GF100-kärnan är uppdelad
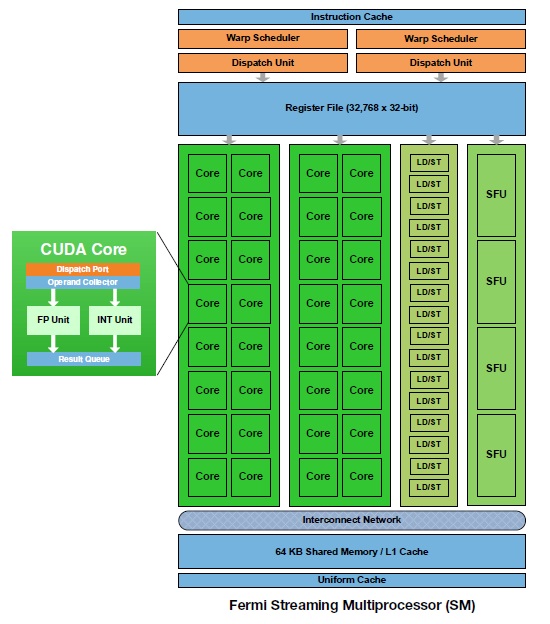
En SM – Streaming Multiprocessor i sina beståndsdelar
Efter en kort genomgång av kärnan känner vi även att en jämförelse mot NVIDIA:s två senaste arkitekturer är på sin plats, som man kanske kan vänta sig ger GF100 de äldre en rejäl omgång, det ser i det närmaste löjligt ut. Detta behöver förstås inte betyda lika dramatiska ökningar i prestanda i samtliga sammanhang, men det är tydligt att NVIDIA satsat hårt på att utveckla sin GF100-kärna för både bästa programmerbarhet (med delat minne/L1-cache samt L2-cache i åtanke) och den tidigare nämnda fysikbiten som bäst översätts till FLOPS, det vill säga Floating Point-uträkningskapacitet.
| GPU | G80 | GT200 | GF100 |
| Transistors | 681M | 1.4B | 3.0B |
| CUDA Cores (Shaders) | 128 | 240 | 512 (480) |
| Double Precision Floating Point Capability | – | 30 FMA ops/clock | 256 FMA ops/clock |
| Single Precision Floating Point Capability | 128 MAD ops/clock | 240 MAD ops/clock | 512 MAD ops/clock |
| Special Function Units/SM | 2 | 2 | 4 |
| Warp Schedulers/SM | 1 | 1 | 2 |
| Shared Memory/SM | 16KB | 16KB | 16/48KB |
| L1 Cache/SM | – | – | 16/48KB |
| L2 Cache | – | – | 768KB |
| ECC Memory Support | No | No | Yes |
| Concurrent Kernels | No | No | Up to 16 |
| Load/Store address width | 32-bit | 32-bit | 64-bit |
En sak som är intressant med GF100 är att man specificerat antalet CUDA Cores till 512, medan toppmodellen som lanseras idag, GTX 480, faktiskt bara har just 480 kärnor aktiverade. Med största sannolikhet beror detta på den extremt komplexa tillverkningsprocessen som innefattar tre miljarder transistorer, vi förmodar helt enkelt att man varit tvungen att göra avkall på en del av kärnorna för att få en hygglig andel fungerande GPU:er från fabrik istället för att repetera GeForce GTX 280-lanseringen där tillgången var väldigt skral de första månaderna på grund av den nya, svårtillverkade arkitekturen.
När det kommer till minneshantering är faktiskt Fermi väldigt lik en helt vanlig CPU du finner i en dator. Den är utrustad med delat minne, L1- och L2-cache och en 384-bits minnesbuss till vilken man sedan fäster GDDR5-minne (för första gången hos NVIDIA) och för första gången i grafikhistoria stöds faktiskt ECC-buffrat minne.
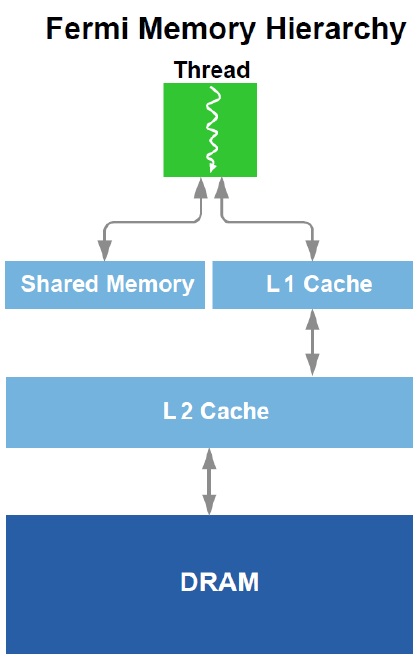
Fermis minneshierarki
Utöver detta har NVIDIA jobbat hårt på sin GigaThread-teknik vilket är ett sätt att exekvera flera kernels samtidigt, likt dagens CPU:er, för att utnyttja GPU:ns fulla kapacitet, istället för att rada upp dessa i kö. En väldigt intuitiv illustration av detta finns nedan.
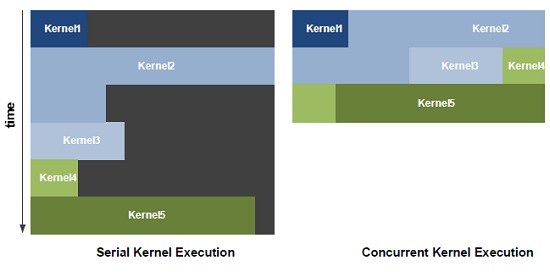
GigaThread i GF100 – exekverar dina kernels utan väntan
Efter denna genomgång av GF100 och dess arkitektur ska vi återbekanta oss med DirectX11 och dess features samt kolla var man hamnar jämfört med konkurrensen.






