













Faster texture units and 1600 shader processors
With twice as many transistors AMD affords to introduce several performance optimizations, among others doubling the number of Shader units (stream processors) from 800 to 1600. It has achieved this by installing 20 SIMD cores with the same number of thread processors as in RV770, 16 per SIMD core. Each thread processor controls 5 stream processors, which adds up to 1600 stream processors all in all and theoretic performance at 2.7TFLOPS in single precision and 544 GFLOPS in double precision.
Despite double the stream processors count we see that the theoretic performance has increased more than that, from 1.2TFLOPs to 2.7TFLOPs. This hints of the other improvements AMD has made, which is a lot more than just increasing the number of stream processors. It has also improved performance of the individual SIMD cores that make out the very foundation of the GPU architecture.
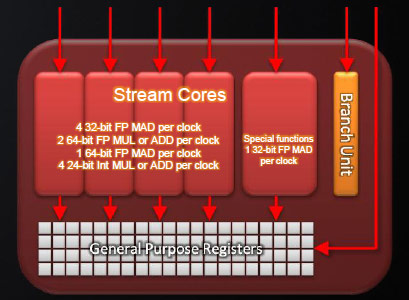
AMD’s optimized SIMD core from RV870, 20 are found in the Radeon HD 5870 GPU
Faster texture units and more efficient antialiasing
Both texture units and ROPs (Raster OPerations) have been doubled and if we look at the texture units (TMU) AMD hasn’t just increased the bandwidth but also revised the local cache. The L1 cache that sits in direct connection to the texture units reach speeds near 1TB/s while the twice as large 128KB L2 cache can feed the L1 cache with 435GB/s. The texture units have been upgraded to support larger textures (16k x 16k resolution) and other functions required by DirectX 11.
|
RV770
|
RV870
|
|
| Texture units | 40. | 80. |
| L1 cache bandwidth | 480GB/s | 1,000GB/s |
| L1 to L2 bandwidth | 384GB/s | 435GB/s |
ROPs, or Render Back-Ends, that AMD calls them have also been optimized an offer twice the performance of the RV770 architecture. This is noticed very well when antialiasing comes into play, where 8xMSAA will now result in performance drops of at most 5-15%. AMD made great progress with antialiasing with RV770 already but with RV870 it has went even further and even introduced a new AA algorithm that without performance hits offers good edge smoothening no matter the angle, which has been problematic in the past.
 The optimized texture units |
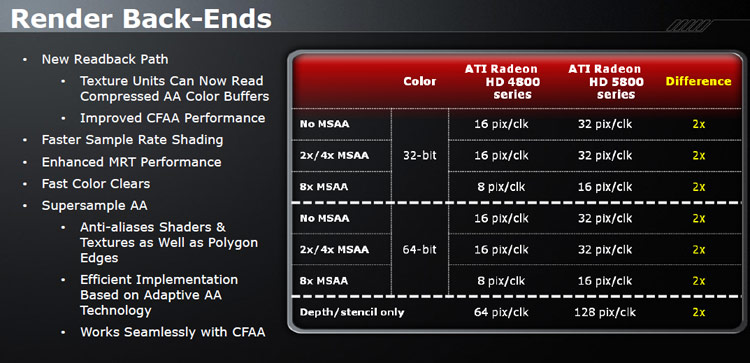 Improved antialiasing performance |





